EventBridge -> SNS Topic -> Email とした場合に、メールの件名が全て "AWS Notification Message" になります。本文は Event の JSON です。
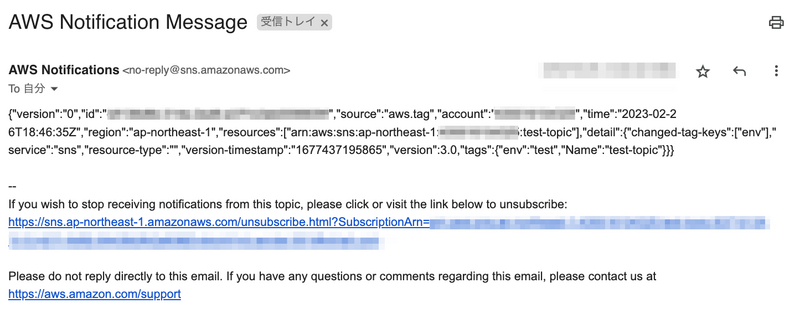
これを、AWS Chatbot のように通知設定を一箇所にして、そこに投げればイベント毎の細かな整形は行わずともどのイベントも良い感じに整形して通知できる。と良いなと思いました。
(Eメールで受け取る是非は今回は置いておきます。)
方式検討
要望は多いようで、既に様々なパターンが紹介されています。
AWS公式では Lambda Function を介した方法が挙げられています。
Lambda Function は柔軟な変更が可能ですが、コード・ライブラリバージョンの管理が必要です。
EventBridge の Input transformer は各Event毎に設定していく必要が出てきます。
また、EventBridge であまりにも緩いルールを使用すると無限ループの可能性があり、トリガーとなるイベントは適切にフィルタすべきなので、必然的にEventBridge のルールは複数使うことになります。
参考: Amazon EventBridge イベントパターンでのコンテンツのフィルタリング
EventBridge -> Step Functions
イメージです。
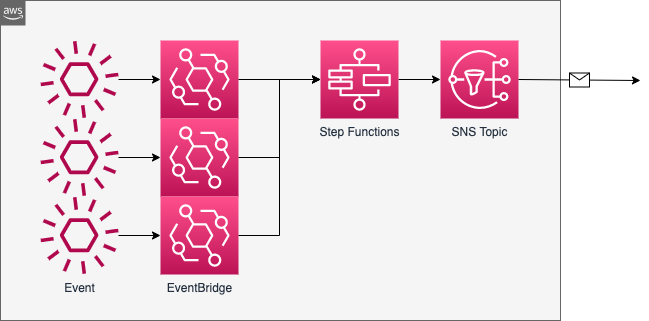
Input transformer を使わず、EventBridgeはただ投げるだけ、変換処理は Step Functions で行うようにすれば通知設定を一箇所にできそうです。
前段に Custom Event Bus を持たせればクロスリージョン・クロスアカウントでも利用できます。
Definition
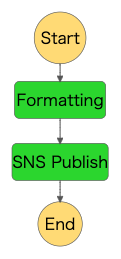
State Machine の定義例です。
Pass で件名と本文を組み込み関数 States.Format を利用して変換、TaskでSNSへ送信します。
{
"Comment": "A description of my state machine",
"StartAt": "Formatting",
"States": {
"Formatting": {
"Type": "Pass",
"Parameters": {
"subject.$": "States.Format('{} | {} | Account: {}', $['detail-type'], $.region, $.account)",
"message.$": "States.Format('source:\n {}\nresources:\n {}\ndetail:\n {}\n\nraw json:\n{}', $.source, $.resources, $.detail, $)"
},
"ResultPath": "$.generate",
"Next": "SNS Publish"
},
"SNS Publish": {
"Type": "Task",
"Resource": "arn:aws:states:::sns:publish",
"Parameters": {
"Subject.$": "$.generate.subject",
"Message.$": "States.Format('# {}\n\n{}', $.generate.subject, $.generate.message)",
"TopicArn": "arn:aws:sns:ap-northeast-1:123456789012:test-topic"
},
"End": true
}
}
}
メール件名部分
Chatbot のメッセージを参考に "件名 | リージョン | アカウント" の形式に変換します。
件名は detail-type で何のイベントが発生したのかが判別できるようにしています。
"subject.$": "States.Format('{} | {} | Account: {}', $['detail-type'], $.region, $.account)"
メール本文部分
全てのイベントに当てはまる(キーが存在する)のかまでは確認していませんが、
件名に入れた情報に加えて、resources があるとイベント発生の対象となったリソースがわかります。
detail 部分の JSON は Pretty(整形) 出力したかったのですが、Step Function 単体では行えないようだったのでそのままの形にしています。
ここは各 Event によりキーが変わるので抽出などは行っていません。
raw json 部分は無くとも良いのですが、利用していないキーの値なども見れるよう変換前の値を末尾に持たせています。
"message.$": "States.Format('source:\n {}\nresources:\n {}\ndetail:\n {}\n\nraw json:\n{}', $.source, $.resources, $.detail, $)"
件名に利用した値も本文に載せたいため、送信時に変換後の件名を結合しています。
"Message.$": "States.Format('# {}\n\n{}', $.generate.subject, $.generate.message)",
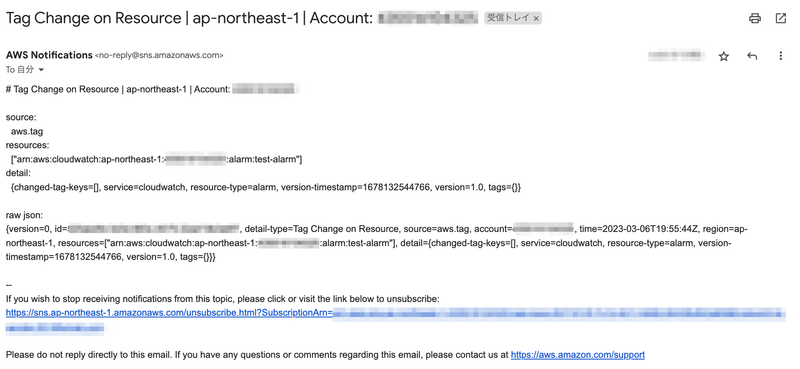
受信結果
件名と本文前半でどのリソースで何が起きたかがある程度判別できるようになったと思います。
応用例
Step Functions に処理を持たせておくことで、柔軟に変更が可能かと思います。
最終的にコードに落とすとしても、ビジュアルエディタ (Workflow Studio) 上で変更を簡単に行えるのは利点ではないでしょうか。
以下はエラー処理やイベント毎の整形を変更するなどを追加した例です。
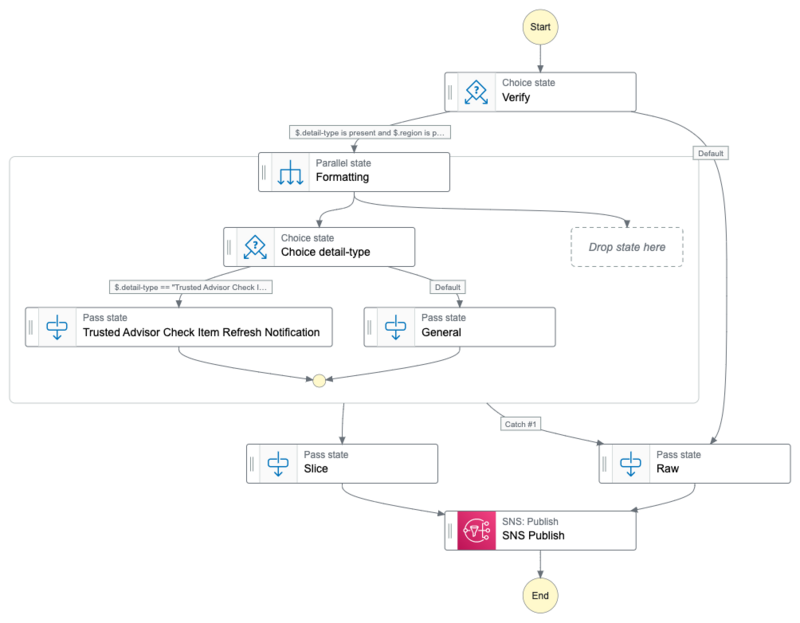
以下端折りますが各タスクの補足です。
Verify
キーが存在しないとランタイムエラーとなってしまうため処理に使用するキーの存在を事前にチェックしておきます。
"Verify": {
"Type": "Choice",
"Choices": [
{
"And": [
{
"Variable": "$.detail-type",
"IsPresent": true
},
{
"Variable": "$.region",
"IsPresent": true
},
...
],
"Next": "Formatting"
}
],
"Default": "Raw"
},
イベント毎の整形に対応させています。
何かしらのエラーになった場合は、後述 Raw の異常系処理に流れるようにしています。
"Formatting": {
"Type": "Parallel",
"Next": "Slice",
"Branches": [
...
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Comment": "Formatting Error",
"Next": "Raw",
"ResultPath": "$.errors"
}
]
Choice detail-type
detail-type での分岐を行います。
"Choice detail-type": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.detail-type",
"StringEquals": "Trusted Advisor Check Item Refresh Notification",
"Next": "Trusted Advisor Check Item Refresh Notification"
}
],
"Default": "General"
},
Trusted Advisor Check Item Refresh Notification
Trusted Advisor は us-esat-1 固定でイベントが作成されるため、件名から region を除外しています。
General
else(Default) に該当する場合の前述 "メール本文部分" の処理を行います。
Slice
SNS Publish 1タスクで正常系と異常系の両方を処理させるため、Parallel state の結果から値を抽出して形を合わせています。
"Slice": {
"Type": "Pass",
"Next": "SNS Publish",
"InputPath": "$[0]"
},
Raw
異常系処理です。
整形処理を行わず、EventBridge から受け取った値をそのまま SNS Topic へ送信します。
"Raw": {
"Type": "Pass",
"Parameters": {
"subject": "AWS Notification Message",
"message.$": "$"
},
"ResultPath": "$.generate",
"Next": "SNS Publish"
},
SNS Publish
SNS Topic への送信処理です。
今回の例では固定にしていますが、TopicArn を渡すようにすれば送信先の振り分けも行えます。