Terraform の実行結果を Slack へ通知したくなり、 tfnotify を使わせてもらいました。
tfnotify は GitHubへの通知がメインのようで、
Slack への通知は README の通りだと微妙な通知になったので試した結果を残しておきます。
環境
Terraform, Slack のバージョンにより挙動は変わると思います。
試行した環境は以下のとおりです。
- Terraform: v1.0.x
- tfnotify: v0.7.0
- Slack: 2021/09時点
Slack設定
Token と Channel ID が必要になります。
- Slack API: Applications
- "Create New App"
- "From scratch"
- "App Name"
tfnotify など、Slack通知時のユーザ名
- "Pick a workspace to develop your app in:"
- 作成した App の詳細ページ (作成時に遷移)
- "OAuth & Permissions"
- "Bot Token Scopes"
chat:write, chat:write.public
- "OAuth Tokens for Your Workspace"
- "Install to Workspace"
- Workspaceへの追加許可ページに遷移
- "Bot User OAuth Token" に Token が発行される
- Slack クライアント または Web
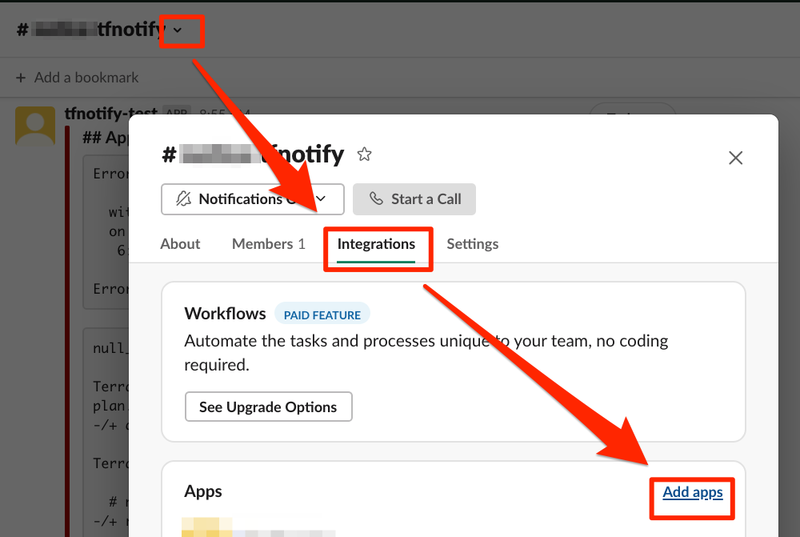
- "Apps" -> "Add apps"
- 通知したいチャンネルを選択
- "Integrations" -> "Add apps"
- 追加した App を選択
チャンネルID
チャンネルの URL に記載されています。
Slack クライアントの場合、左ペインの対象チャンネルを右クリック -> "Copy link" から取得できます。
# 例 ( XXXXXXXXXXX の部分がチャンネルID)
https://example.slack.com/archives/XXXXXXXXXXX
基本形
- README 記載の .tfnotify.yaml
---
ci: codebuild
notifier:
slack:
token: $SLACK_TOKEN
channel: $SLACK_CHANNEL_ID
bot: $SLACK_BOT_NAME
terraform:
plan:
template: |
{{ .Message }}
{{if .Result}}
```
{{ .Result }}
```
{{end}}
```
{{ .Body }}
```
実行
terraform plan | tfnotify plan
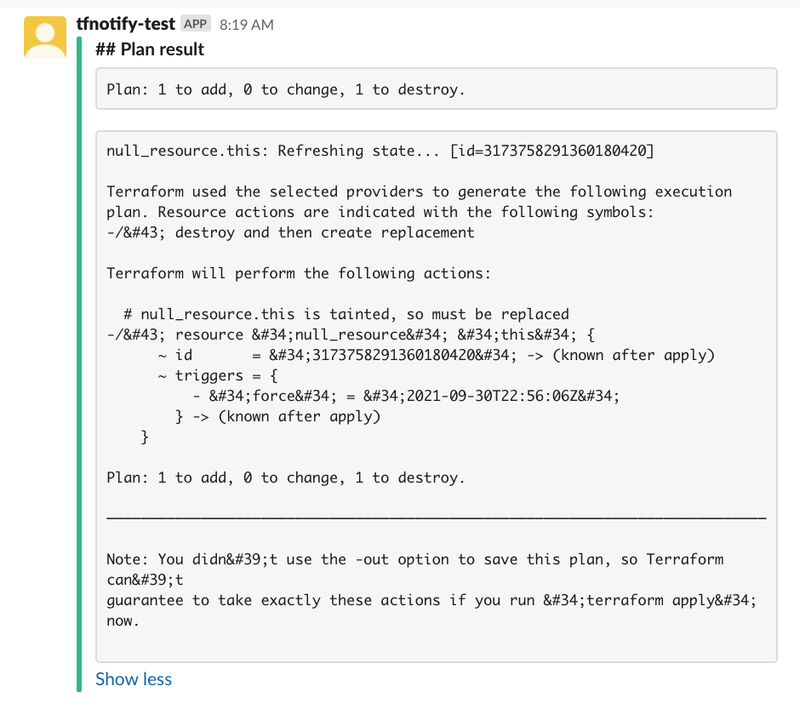
実行結果
文字化けしてます。
文字化け(HTMLエスケープ)の解消
tfnotify 内で HTML エスケープを行っており、それがそのまま変換されず出力されています。
README 内の GitHub の箇所に use_raw_output オプションの記載があります。
これを適用することで解消できそうでしたが、対応しているのは GitHub のみでした。
そのため Slack用の PR を挙げました。
PR がマージされることを願いつつ、インストールします。
git clone https://github.com/htnosm/tfnotify.git
cd tfnotify && go build
terraform:
use_raw_output: true
plan:
実行
terraform plan | tfnotify plan
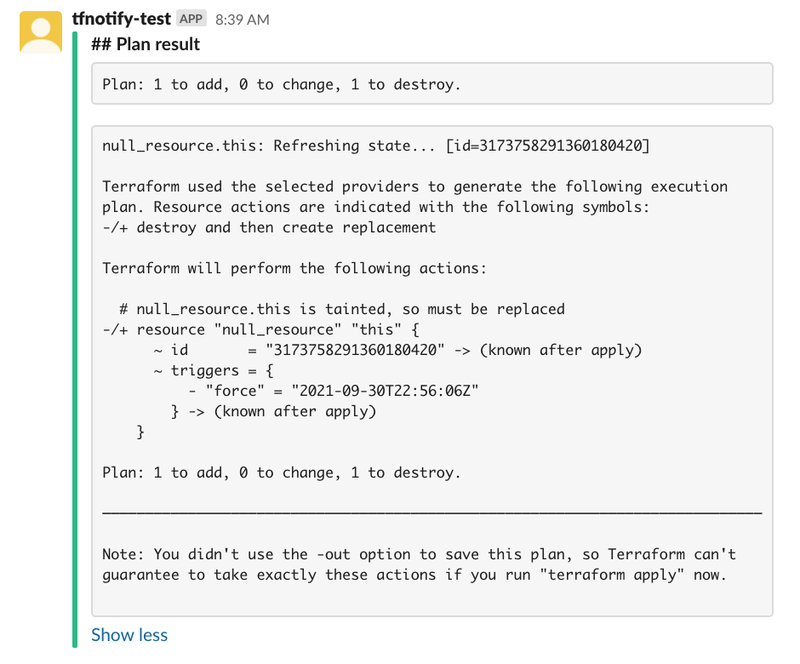
実行結果
文字化けが解消できます。
apply
In the case of apply, you need to do apply.
とありますので、applyを指定、設定も planとは別に apply の定義を追加します。
- .tfnotify.yaml に apply 追加
terraform:
use_raw_output: true
plan:
apply:
template: |
{{ .Message }}
{{if .Result}}
```
{{ .Result }}
```
{{end}}
```
{{ .Body }}
```
実行
terraform apply | tfnotify apply
実行結果
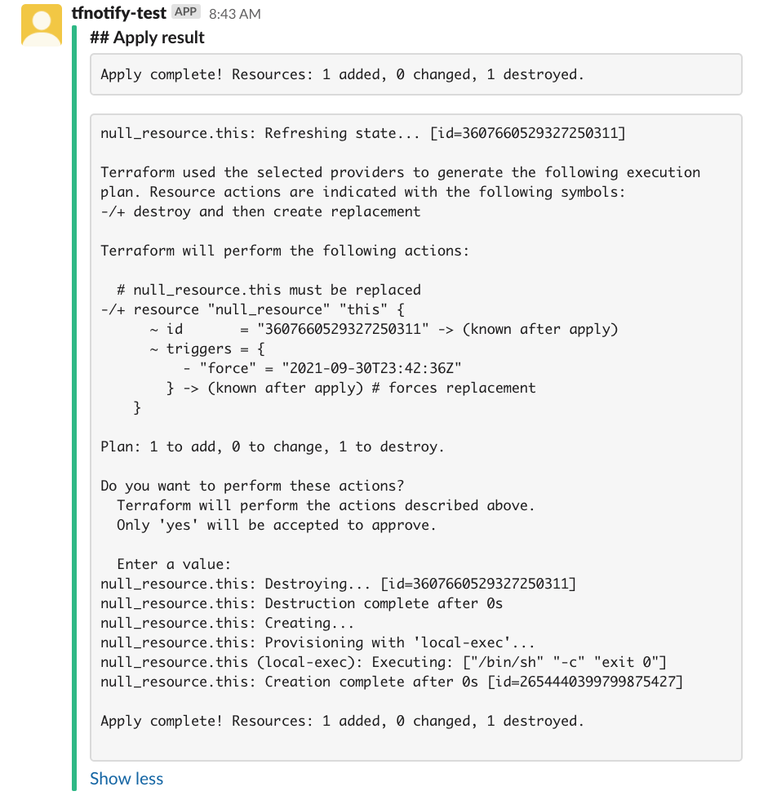
エラー通知
Terraform でエラーが発生した場合に通知ができませんでした。
tfnotify が以下を出力します。
cannot parse apply result
仕様としては、 Error: の文字列で検索しているため通知自体は可能です。( https://github.com/mercari/tfnotify/blob/master/terraform/parser.go#L65 )
条件とそれぞれ対処は以下になります。
実行
terraform apply -no-color 2>&1 | tfnotify apply
実行結果
エラー内容が通知され、色も赤になっており良い感じです。

Refreshing state の除外
管理対象のリソース数が増えてくると、Refreshing state... の行で埋め尽くされます。
複数行パターンでなく、特定の行を除外したいだけであれば tfnotify に渡す前に除外すれば良いです。
terraform plan -no-color 2>&1 | grep -v -e ' Refreshing state\.\.\. ' | tfnotify plan
実行時オプション
グローバルオプションのメモです。
各コマンドのヘルプは tfnotify xxx --help で出力
GLOBAL OPTIONS:
--ci value name of CI to run tfnotify
--config value config path
--notifier value notification destination
--help, -h show help
--version, -v print the version
- ci, notifier
- 実行時に定義済み ci, notifier の選択
- config
- 定義ファイル(.tfnotify.yaml) の指定
- version
- help
- tfnotify xxx --help で各コマンドのヘルプ出力
まとめ
use_raw_output オプションが有効な通知先は限定されている
- エラー通知は以下が必要
- tfnotifyへエラー出力も含めて渡す
- Terraform に
-no-color オプションを付与して実行する
- slack.bot を設定しても置き換わらない(?)
- 設定を入れても Slack App Name のままでした
- 定義ファイルは config オプションで実行時指定ができる